SFS simulation#
fastdfe provides a Simulation module to generate an expected SFS under a specific DFE, and potentially demographic nuisance parameters. In fact, when inferring the DFE with fastdfe, the expected SFS is repeatedly simulated for different parameters to find the maximum likelihood estimates. Below, we illustrate how to use the simulation module to generate SFS data under a given DFE. To do this, we need to specify a neutral SFS (sfs_neut), which is informative on the population sample size, population mutation rate, the number of sites, and possibly demography. get_neutral_sfs() can be used to obtain a neutral SFS under a constant panmictic population. We also specify the DFE parameters and parametrization. By default, we assume not ancestral misidentification (eps=0) and mutation are assumed to be semi-dominant (h=0.5).
library(fastdfe)
fd <- load_fastdfe()
# create simulation object by specifying neutral SFS and DFE
sim <- fd$Simulation(
sfs_neut = fd$Simulation$get_neutral_sfs(n = 20, n_sites = 1e8, theta = 1e-4),
params = list(S_d = -300, b = 0.3, p_b = 0, S_b = 1),
model = fd$GammaExpParametrization()
)
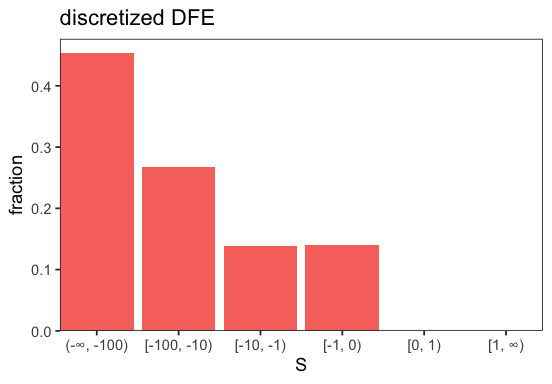
Let’s plot the DFE we are going to use for the simulation which is purely deleterious and follows a gamma distribution.
p <- sim$dfe$plot()
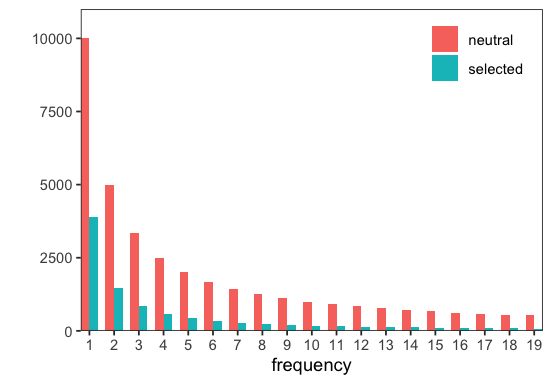
Let’s now run the simulation and plot the expected SFS for both neutral (specified) and selected (simulated) sites.
sfs_sel <- sim$run()
p <- sim$get_spectra()$plot()
INFO:Simulation: Simulating SFS under selection using parameters: S_d=-300, b=0.3, p_b=0, S_b=1, eps=0, h=0.5
INFO:Discretization: Precomputing semidominant DFE-SFS transformation using midpoint integration.
Discretization>Precomputing: 100%|██████████| 19/19 [00:01<00:00, 16.67it/s]
We can now use the simulated SFS to infer the DFE parameters and assess how closely the inference recovers the true DFE used to generate the data.
inf = fd$BaseInference(
sfs_neut = sim$sfs_neut,
sfs_sel = sim$sfs_sel,
fixed_params = list(all = list(eps = 0, h = 0.5, p_b = 0, S_b = 1))
)
sfs_modelled <- inf$run()
p <- fd$DFE$plot_many(c(sim$dfe, inf$get_dfe()), labels = c('True DFE', 'Inferred DFE'))
INFO:BaseInference: No divergence counts provided, inferring from polymorphism only.
INFO:Discretization: Precomputing semidominant DFE-SFS transformation using midpoint integration.
Discretization>Precomputing: 100%|██████████| 19/19 [00:01<00:00, 16.97it/s]
INFO:Optimization: Optimizing 2 parameters: [all.b, all.S_d].
BaseInference>Performing inference: 100%|██████████| 10/10 [00:00<00:00, 99.06it/s]
INFO:BaseInference: Inference results: {all.S_d: -300 ± 0.00083, all.b: 0.3 ± 2.4e-07, all.p_b: 0 ± 0, all.S_b: 1 ± 0, all.eps: 0 ± 0, all.h: 0.5 ± 0, likelihood: -69.67 ± 3e-10} (best_run ± std_across_runs)
BaseInference>Bootstrapping (2 runs each): 100%|██████████| 100/100 [00:01<00:00, 54.63it/s]
INFO:BaseInference: Bootstrap summary: {all.S_d: -303 ± 51, all.b: 0.3009 ± 0.014, all.p_b: 0 ± 0, all.S_b: 1 ± 0, all.eps: 0 ± 0, all.h: 0.5 ± 0, likelihood: -79.35 ± 3.1, i_best_run: 0.53 ± 0.5, likelihoods_std: 0.4026 ± 4} (mean ± std)
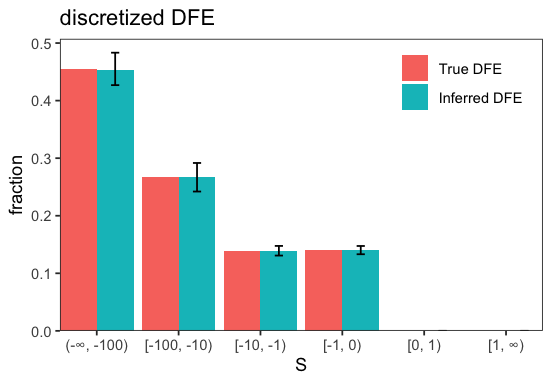
The DFE is recovered quite well which is expected given the simplicity of the DFE parametrization and lack of demographic complications.
We may want to see how the expected SFS changes as we vary the degree of dominance. Here, we run a second simulation with the same parameters except that we set h=0.3 so that mutations are partially recessive.
# run simulation with h=0.3
sim2 <- fd$Simulation(
sfs_neut = fd$Simulation$get_neutral_sfs(n = 20, n_sites = 1e8, theta = 1e-4),
params = list(S_d = -300, b = 0.3, p_b = 0, S_b = 1, h = 0.3),
model = fd$GammaExpParametrization()
)
sfs_sel <- sim2$run()
p <- fd$Spectra$from_spectra(list(
neutral = sim$sfs_neut,
semidominant = sim$sfs_sel,
recessive = sim2$sfs_sel
))$plot()
INFO:Simulation: Simulating SFS under selection using parameters: S_d=-300, b=0.3, p_b=0, S_b=1, h=0.3, eps=0
INFO:Discretization: Precomputing DFE-SFS transformation for fixed h=0.3.
Discretization>Precomputing: 100%|██████████| 3819/3819 [00:43<00:00, 87.39it/s]
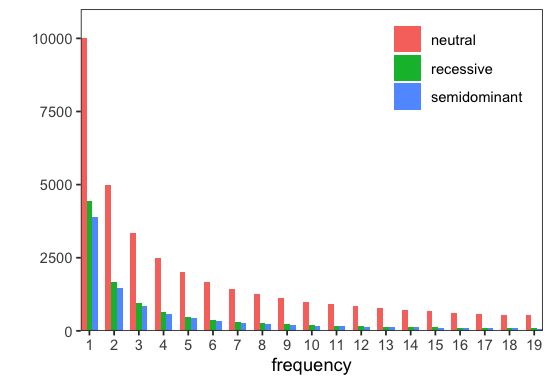
As expected, partially recessive mutations lead to an excess of rare variants because they are masked in heterozygotes and experience weaker purifying selection. At higher frequencies, the difference from the semidominant case diminishes as derived-allele homozygotes become more common.
We can now infer the DFE under the (incorrect) assumption that mutations are semidominant (h=0.5) and see how this affects the inference result.
inf <- fd$BaseInference(
sfs_neut = sim2$sfs_neut,
sfs_sel = sim2$sfs_sel
)
sfs_modelled <- inf$run()
p <- fd$DFE$plot_many(c(sim2$dfe, inf$get_dfe()), labels = c('True DFE (h=0.3)', 'Inferred DFE (h=0.5)'))
INFO:BaseInference: No divergence counts provided, inferring from polymorphism only.
INFO:Discretization: Precomputing semidominant DFE-SFS transformation using midpoint integration.
Discretization>Precomputing: 100%|██████████| 19/19 [00:01<00:00, 16.97it/s]
INFO:Optimization: Optimizing 2 parameters: [all.b, all.S_d].
BaseInference>Performing inference: 100%|██████████| 10/10 [00:00<00:00, 84.87it/s]
INFO:BaseInference: Inference results: {all.S_d: -154.4 ± 0.00028, all.b: 0.3252 ± 2e-07, all.p_b: 0 ± 0, all.S_b: 1 ± 0, all.eps: 0 ± 0, all.h: 0.5 ± 0, likelihood: -71.14 ± 2.7e-10} (best_run ± std_across_runs)
BaseInference>Bootstrapping (2 runs each): 100%|██████████| 100/100 [00:01<00:00, 55.45it/s]
INFO:BaseInference: Bootstrap summary: {all.S_d: -153.3 ± 21, all.b: 0.3275 ± 0.014, all.p_b: 0 ± 0, all.S_b: 1 ± 0, all.eps: 0 ± 0, all.h: 0.5 ± 0, likelihood: -81.25 ± 3.4, i_best_run: 0.48 ± 0.5, likelihoods_std: 0.7301 ± 7.3} (mean ± std)
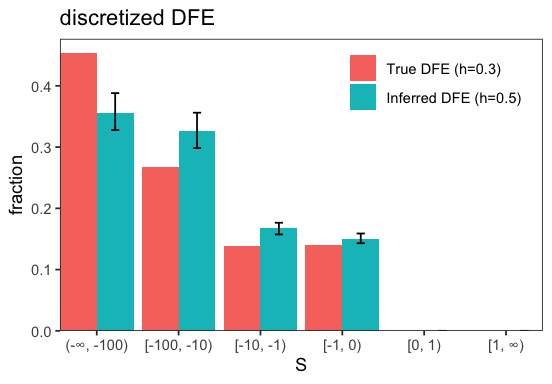
Assuming semidominance when mutations are actually partially recessive leads to an inferred DFE shifted toward weaker selection coefficients. This happens because rare variants generated by recessive mutations are misattributed to weaker selection when the dominance reduction in purifying selection is not accounted for.
We can also try to infer the DFE while letting the dominance coefficient h vary during the optimization. To optimize h, it needs to be discretized; in this example we use the default grid of 21 points between 0 and 1, with intermediate values obtained by linear interpolation. All required values are precomputed before the optimization, but allowing h to vary increases the computational cost because the expected SFS must be simulated for each h in the grid. To speed up the precomputation step, we instruct BaseInference to use a coarser DFE discretization grid than the default, which should be sufficient for most inference scenarios.
inf <- fd$BaseInference(
sfs_neut = sim$sfs_neut,
sfs_sel = sim$sfs_sel,
intervals_h = c(0, 1, 21),
intervals_del = c(-1.0e+8, -1.0e-5, 100),
intervals_ben = c(1.0e-5, 1.0e4, 100),
fixed_params = list(all = list(eps = 0, p_b = 0, S_b = 1))
)
sfs_modelled <- inf$run()
p <- fd$DFE$plot_many(c(sim2$dfe, inf$get_dfe()), labels = c('True DFE (h=0.3)', 'Inferred DFE'))
INFO:BaseInference: No divergence counts provided, inferring from polymorphism only.
INFO:Discretization: Precomputing DFE-SFS transformation across dominance coefficients (grid size: 21).
Discretization>Precomputing: 100%|██████████| 8379/8379 [01:33<00:00, 89.64it/s]
INFO:Optimization: Optimizing 3 parameters: [all.b, all.S_d, all.h].
BaseInference>Performing inference: 100%|██████████| 10/10 [00:00<00:00, 42.46it/s]
INFO:BaseInference: Inference results: {all.S_d: -298.9 ± 0.027, all.b: 0.3003 ± 2.6e-06, all.p_b: 0 ± 0, all.S_b: 1 ± 0, all.eps: 0 ± 0, all.h: 0.5021 ± 3.6e-05, likelihood: -69.67 ± 1.8e-08} (best_run ± std_across_runs)
BaseInference>Bootstrapping (2 runs each): 100%|██████████| 100/100 [00:04<00:00, 22.20it/s]
INFO:BaseInference: Bootstrap summary: {all.S_d: -2874 ± 1.3e+04, all.b: 0.2873 ± 0.036, all.p_b: 0 ± 0, all.S_b: 1 ± 0, all.eps: 0 ± 0, all.h: 0.4651 ± 0.26, likelihood: -78.72 ± 3, i_best_run: 0.51 ± 0.5, likelihoods_std: 0.02197 ± 0.17} (mean ± std)
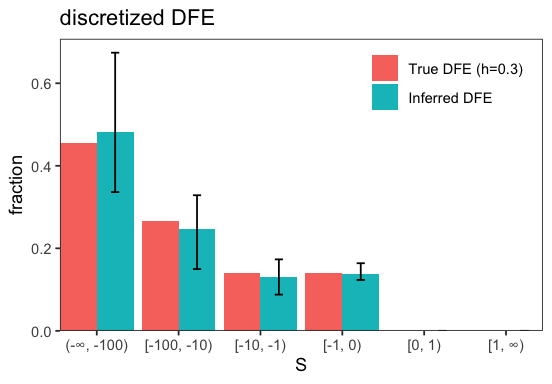
We see that allowing h to vary during inference roughly recovers the true DFE used for the simulation, but with substantially greater uncertainty. Finally, we can examine the bootstrap results to assess how well h was estimated.
hist(inf$bootstraps$h)
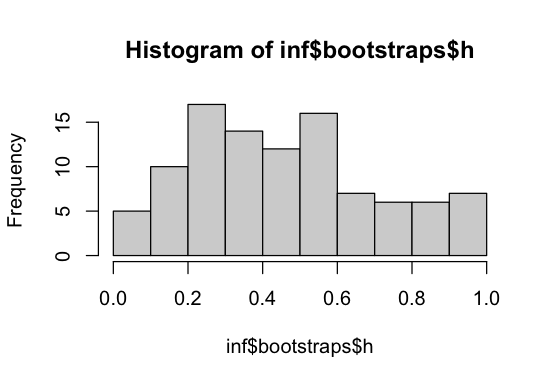
We see that h was estimated with considerable uncertainty, but the bootstrap distribution still puts substantial mass near the true value h = 0.3. How well dominance can be inferred from SFS data alone remains an open question, especially when the DFE is more complex or additional nuisance parameters such as demography are included.
plot(abs(inf$bootstraps$S_d), inf$bootstraps$h, log="x")
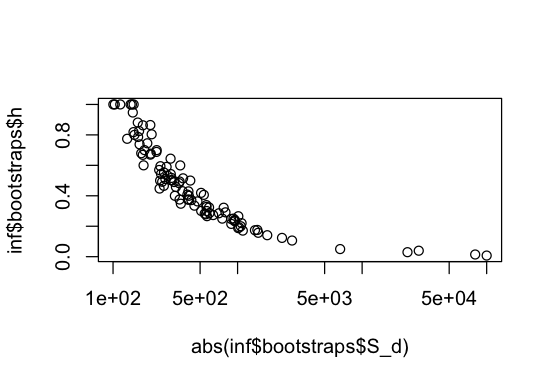
Indeed, we see that h covaries with S_d, with larger h associated with less strongly deleterious mutations.